生图提示词:
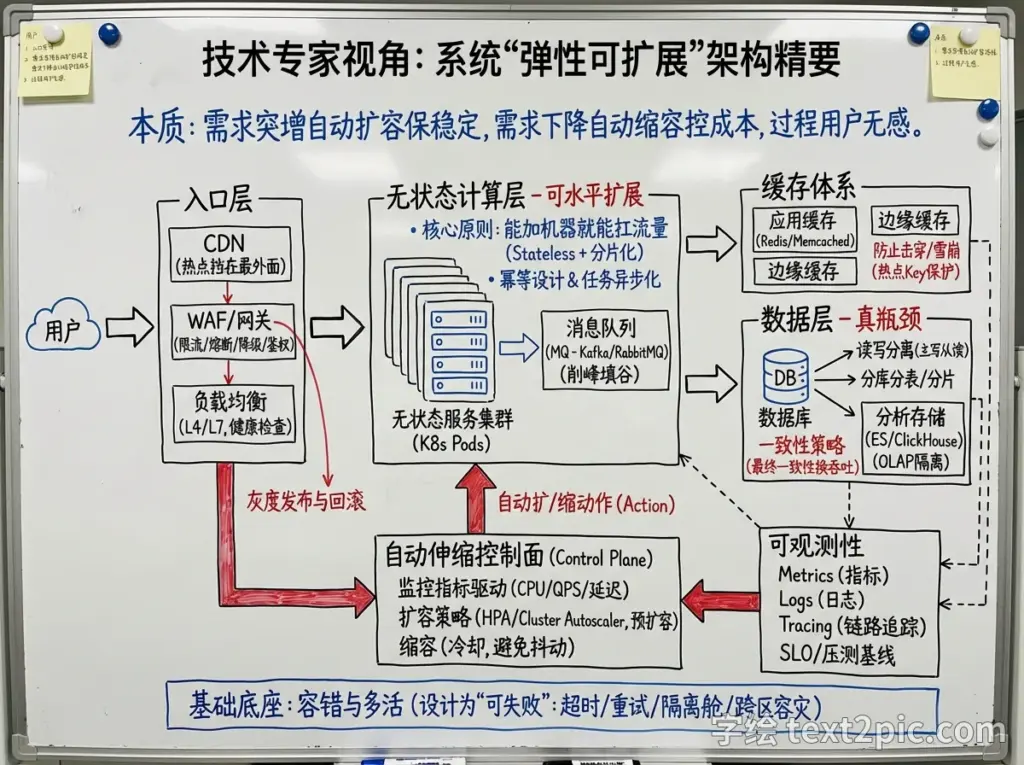
制作一幅办公室白板插图,用用带标签的箭头和清晰易读的简体中文总结解释下面文字内容,”’从技术专家视角讲,“弹性可扩展”本质是:需求突增时自动扩容保持稳定,需求下降时自动缩容控制成本,并且扩/缩过程对用户尽量无感。要做到这一点,一般要把系统拆成几层来设计:无状态计算层 + 可水平扩展的数据层 + 可承压的入口与缓存 + 可观测与自动化控制面。
1) 先把“计算”做成可水平扩展:无状态化 + 分片化
核心原则:能加机器就能扛流量。
无状态服务(Stateless):请求不依赖本机内存会话;会话放到 Redis/DB 或使用 JWT;文件放对象存储。
水平扩展(Scale out):同一个服务跑多副本,靠负载均衡分发。
幂等与重试安全:扩容/故障切换会增加重试、重复请求,接口需做到幂等(比如用幂等键/去重表)。
任务异步化:把慢操作从请求链路挪到队列/事件流(Kafka/RabbitMQ/SQS),由 worker 弹性伸缩处理。
一句话:让服务像“乐高积木”,多插几块就更强。
2) 入口层抗压:负载均衡 + 限流 + 灰度
入口是流量洪峰第一线。
多级负载均衡:L4(连接级)+ L7(HTTP/路由级);支持健康检查、权重、就近接入。
限流/熔断/降级:
限流:保护后端(令牌桶/漏桶/分布式限流)。
熔断:下游异常时快速失败,避免雪崩。
降级:高峰时关掉非核心能力(推荐、画像、非关键报表)。
灰度发布与回滚:避免发布导致大面积故障(分批、按比例、按用户标签)。
3) 缓存体系:把“热点”挡在最外面
弹性扩展不是只靠加机器,缓存能把扩容需求砍掉一大截。
CDN:静态资源、图片、视频、甚至可缓存的 API(注意缓存键与失效策略)。
边缘缓存/反向代理缓存(如 Nginx/Varnish):减少应用层压力。
应用缓存(Redis/Memcached):
热点 Key 保护:本地缓存 + 请求合并 + 互斥锁,避免缓存击穿。
预热与过期抖动:防止同一时刻大规模失效造成“缓存雪崩”。
4) 数据层才是“真瓶颈”:读写扩展、分库分表、隔离
计算层好扩,数据层扩展更难,所以必须提前做架构策略。
读写分离:主写从读;读流量用副本扛。
分库分表/分片:按用户、业务键做分片,单库上限提前规划。
索引与查询治理:慢查询是扩展杀手;要有慢查询审计与自动告警。
隔离:把“核心交易库”和“分析/报表”分开;OLTP/OLAP 分离(数仓/ES/ClickHouse 等)。
一致性策略:并不是所有场景都要强一致;能用最终一致就换取吞吐与可用性。
5) 自动伸缩的“控制面”:监控指标驱动扩/缩容
弹性不是“手工加机器”,而是由指标触发的自动化闭环。
扩容触发指标(常见组合):
CPU/内存只是粗指标,更关键的是:QPS、P95/P99 延迟、队列堆积长度、错误率、连接数。
伸缩策略:
HPA(按负载扩 Pod)+ Cluster Autoscaler(扩节点)
队列驱动扩容(根据 backlog 扩 worker)
预扩容(大促/活动前按预测提前拉起)
缩容要更谨慎:设置冷却时间、渐进缩容,避免抖动(thrashing)。
6) 容错与多活:扩展的前提是“可失败”
流量越大,“坏事”发生概率越高,所以必须设计成可失败系统。
超时、重试、退避、隔离舱壁(bulkhead)
故障转移:同城多 AZ、跨区域容灾;数据库备份与演练
数据与依赖治理:任何下游都可能成为瓶颈,必须有“保护上游”的机制
7) 可观测性与容量规划:知道自己还能扛多少
没有可观测,弹性伸缩就是盲飞。
三大件:Metrics(指标)+ Logs(日志)+ Tracing(链路追踪)
SLO/错误预算:用目标驱动工程决策(比如 P95<200ms、可用性 99.9%)
压测与容量模型:定期压测,形成“每台机器能扛多少”的基线,活动前做容量评估。
8) 一个“参考落地架构”长什么样
典型互联网服务的弹性链路:
用户 → CDN → WAF/网关(限流、鉴权)→ 负载均衡 → 无状态服务集群(K8s/HPA)
→ 缓存 Redis(热点、会话、分布式锁)→ 消息队列(异步削峰)
→ 数据库(读写分离/分片)+ 搜索/分析存储(ES/ClickHouse)
→ 监控告警 → 自动扩缩容与发布系统(灰度/回滚)”’
把上面提示词贴到下面连结可以作同款图